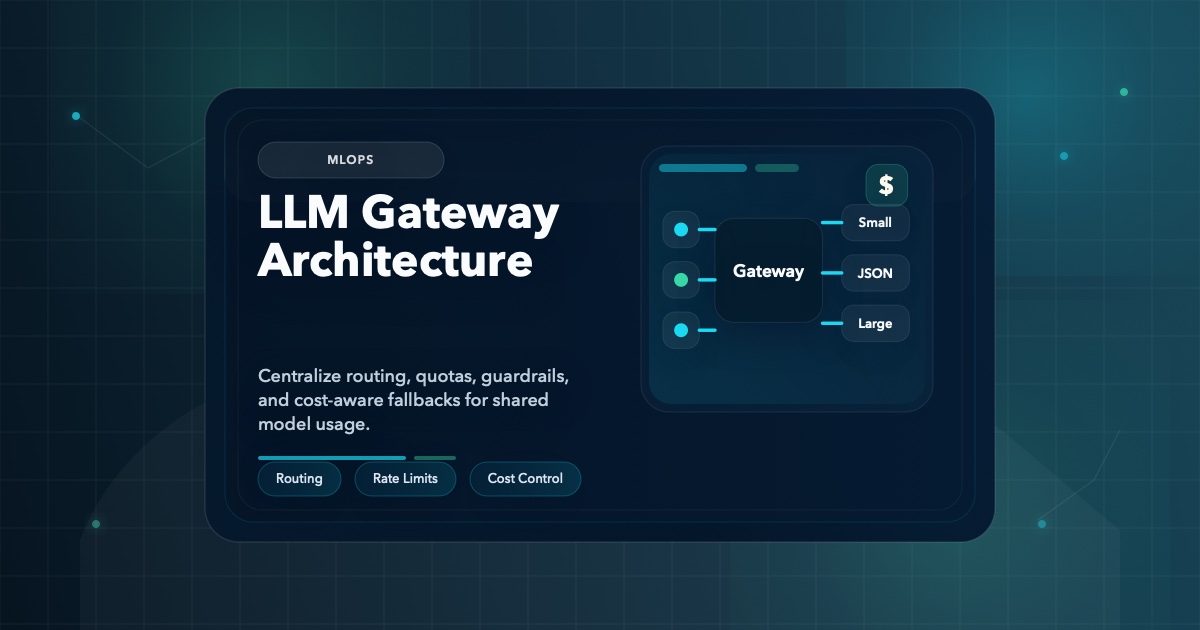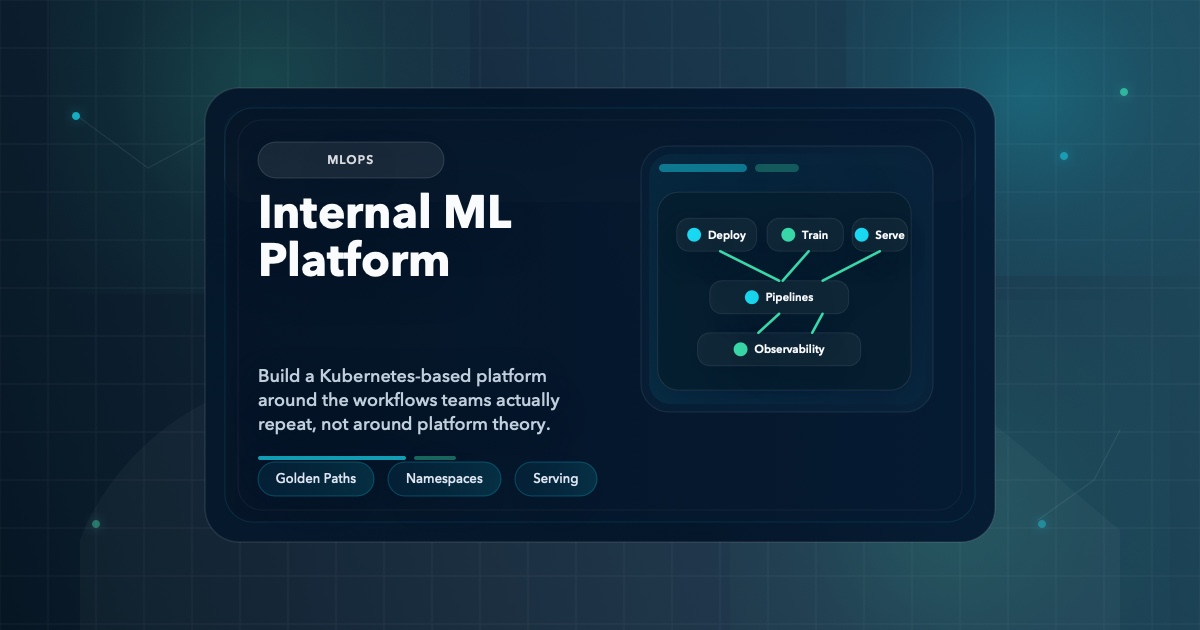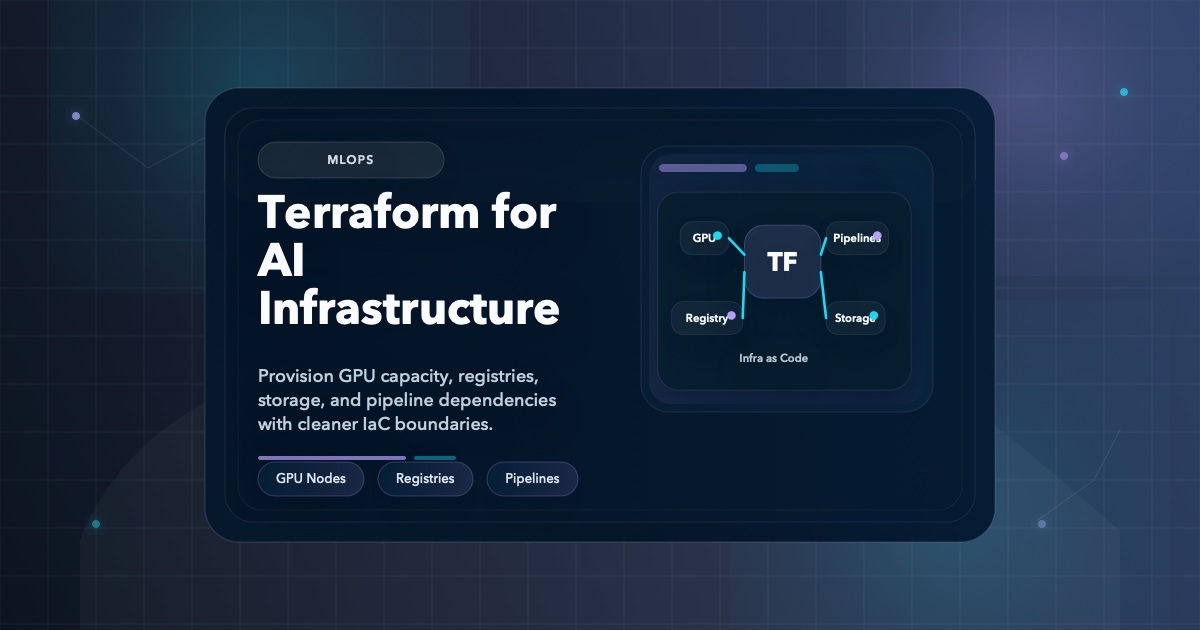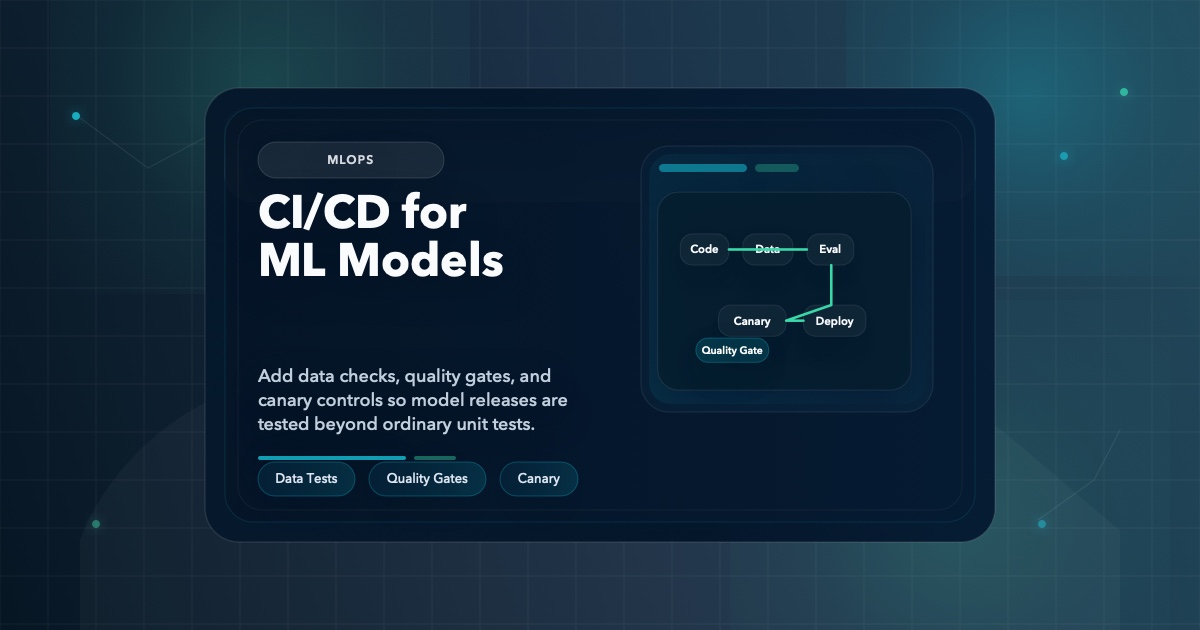
MLOps
5 min read
AI Observability: Metrics and Dashboards That Actually Matter
A practical guide to AI observability for production systems — including latency, drift, token usage, retrieval quality, and the dashboards teams actually use during incidents.