MLOps
5 min read
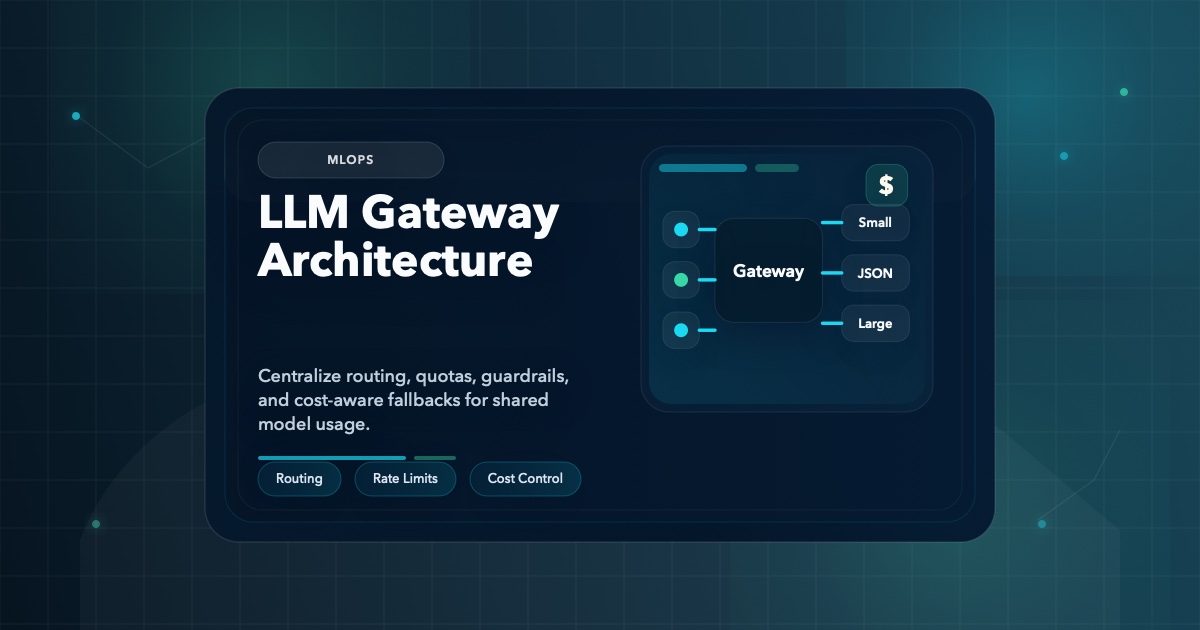
LLM Gateway Architecture: Routing, Rate Limits, and Cost Controls
How to design an LLM gateway for production use cases, including multi-model routing, guardrails, quotas, usage logging, and cost-aware fallbacks.
We share everything we learn — real use cases, real production lessons. Technical deep-dives on MLOps, model deployment, AI reliability, and more.
📝 Building in public
Posts authored by the Resilio Tech Team. More in-depth tutorials and case studies coming soon.
How to design an LLM gateway for production use cases, including multi-model routing, guardrails, quotas, usage logging, and cost-aware fallbacks.
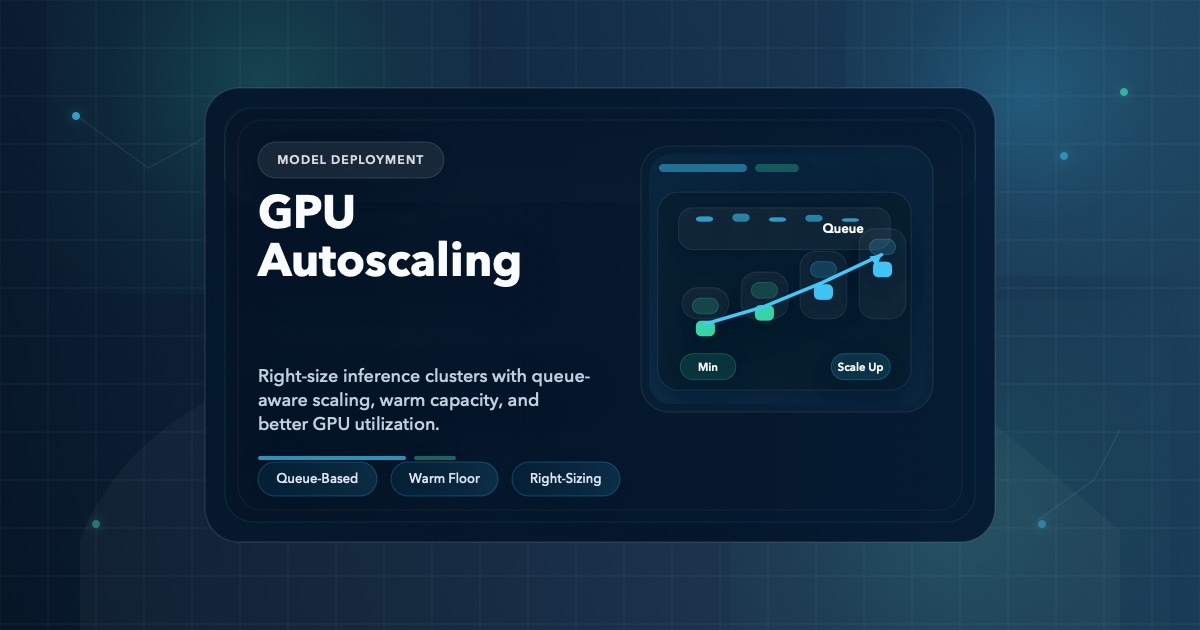
How to autoscale GPU-backed inference clusters without wasting money, including queue-based scaling, warm capacity, and right-sizing by workload profile.

Practical strategies for reducing GPU infrastructure costs — covering spot instances, GPU scheduling, model optimization, and right-sizing — without degrading inference quality.

How to measure token-level inference spend in production and add practical controls around prompt size, output limits, routing, caching, and tenant budgets.
3/30/2026 • 6 min read
3/29/2026 • 8 min read
3/28/2026 • 6 min read
3/27/2026 • 5 min read