
Model Deployment
8 min read
Serving Open-Source LLMs with vLLM on Kubernetes
A practical guide to deploying open-source LLMs with vLLM on Kubernetes — covering GPU sizing, request routing, autoscaling, batching, and safe rollouts.
We share everything we learn — real use cases, real production lessons. Technical deep-dives on MLOps, model deployment, AI reliability, and more.
📝 Building in public
Posts authored by the Resilio Tech Team. More in-depth tutorials and case studies coming soon.
A practical guide to deploying open-source LLMs with vLLM on Kubernetes — covering GPU sizing, request routing, autoscaling, batching, and safe rollouts.

A practical guide to rolling out ML models safely in production using shadow traffic, canary promotion, quality gates, and fast rollback paths.

A hands-on guide to building production MLOps pipelines on Kubernetes — covering CI/CD for models, automated retraining, model registry integration, and deployment strategies.
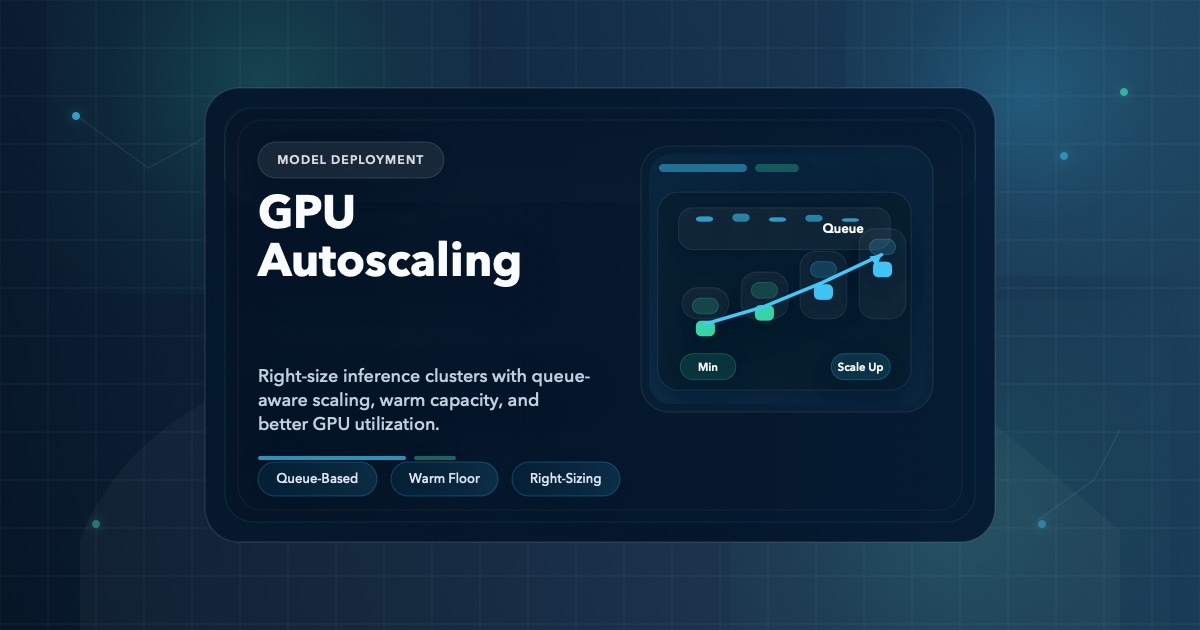
How to autoscale GPU-backed inference clusters without wasting money, including queue-based scaling, warm capacity, and right-sizing by workload profile.

Practical strategies for reducing GPU infrastructure costs — covering spot instances, GPU scheduling, model optimization, and right-sizing — without degrading inference quality.

How to serve many ML models on shared infrastructure without noisy-neighbor problems, unpredictable latency, or runaway GPU spend.

Why standard API load-testing assumptions break for LLM inference, and how to design tests that reflect token generation, concurrency, and real serving bottlenecks.
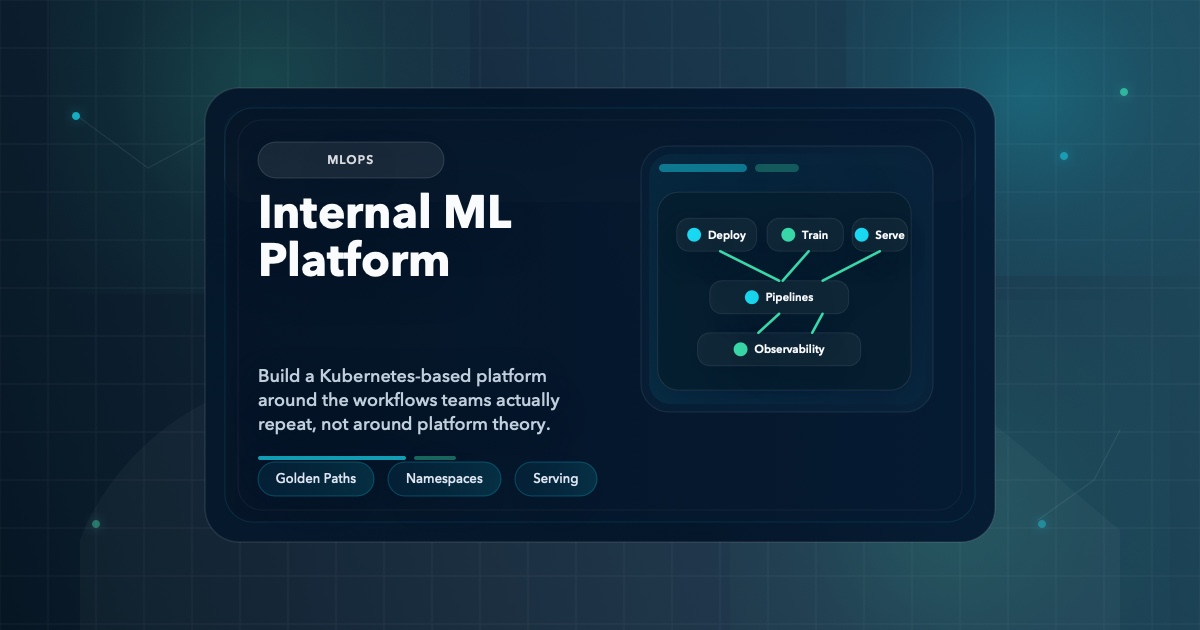
A pragmatic guide to internal ML platforms on Kubernetes, covering the patterns that reduce platform sprawl and the abstractions teams actually use in production.

How to measure token-level inference spend in production and add practical controls around prompt size, output limits, routing, caching, and tenant budgets.
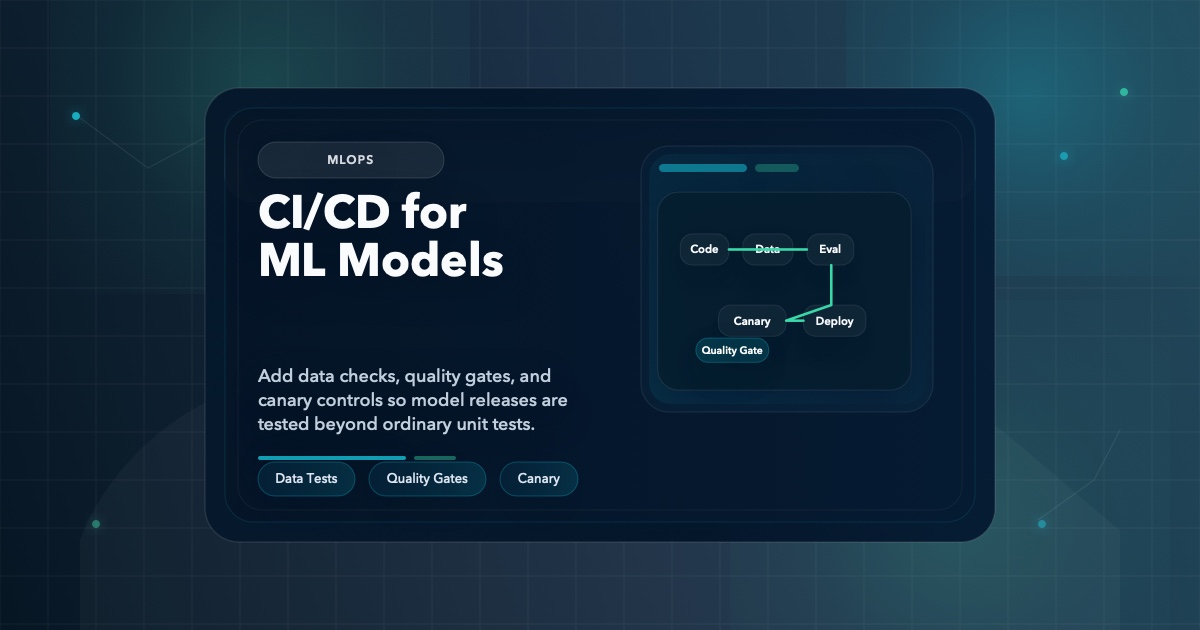
How to build CI/CD for ML systems with data validation, schema checks, shadow evaluations, and deployment gates that go beyond ordinary application unit tests.
3/30/2026 • 6 min read
3/29/2026 • 8 min read
3/28/2026 • 6 min read
3/27/2026 • 5 min read