AI Reliability
6 min read
Production RAG Systems: A Reliability Checklist
Most RAG systems work in demos and fail in production. Use this checklist to harden retrieval, chunking, evaluation, freshness, and guardrails before users feel the gaps.
We share everything we learn — real use cases, real production lessons. Technical deep-dives on MLOps, model deployment, AI reliability, and more.
📝 Building in public
Posts authored by the Resilio Tech Team. More in-depth tutorials and case studies coming soon.
Most RAG systems work in demos and fail in production. Use this checklist to harden retrieval, chunking, evaluation, freshness, and guardrails before users feel the gaps.

A practical guide to deploying open-source LLMs with vLLM on Kubernetes — covering GPU sizing, request routing, autoscaling, batching, and safe rollouts.
Most ML models that work in notebooks break in production. Learn the top reasons for production ML failures — model drift, infrastructure gaps, and monitoring blind spots — and how to fix them.
A practical guide to AI observability for production systems — including latency, drift, token usage, retrieval quality, and the dashboards teams actually use during incidents.

A practical guide to rolling out ML models safely in production using shadow traffic, canary promotion, quality gates, and fast rollback paths.

A hands-on guide to building production MLOps pipelines on Kubernetes — covering CI/CD for models, automated retraining, model registry integration, and deployment strategies.

How to build practical incident response runbooks for production AI systems, including triage flows for latency spikes, drift, bad outputs, and model-serving failures.
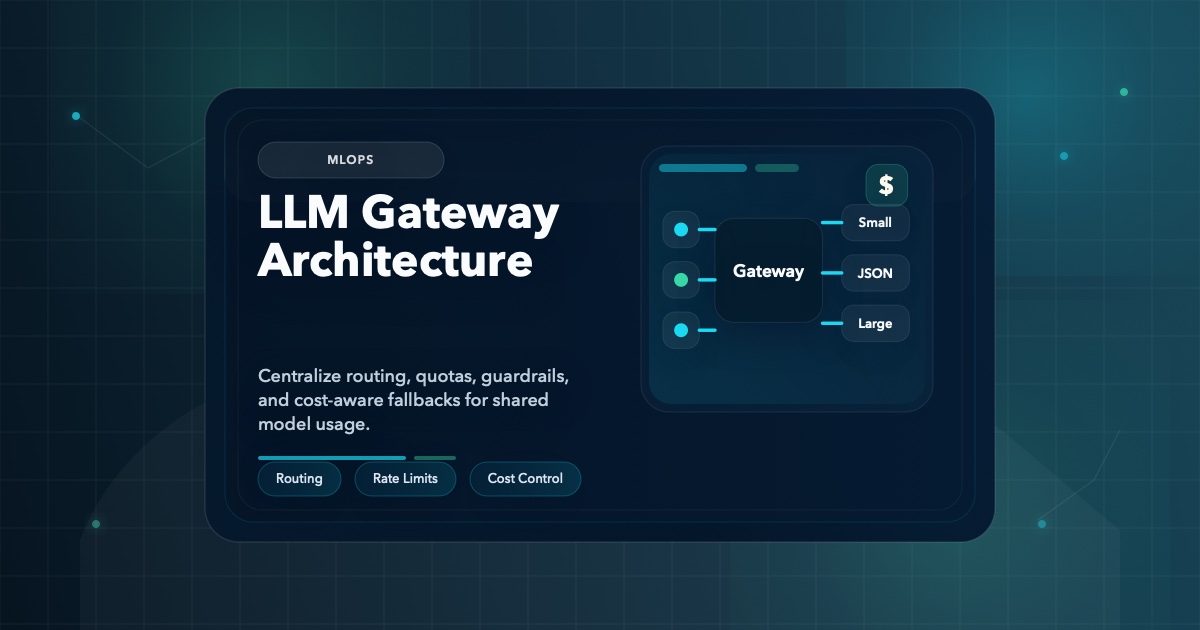
How to design an LLM gateway for production use cases, including multi-model routing, guardrails, quotas, usage logging, and cost-aware fallbacks.
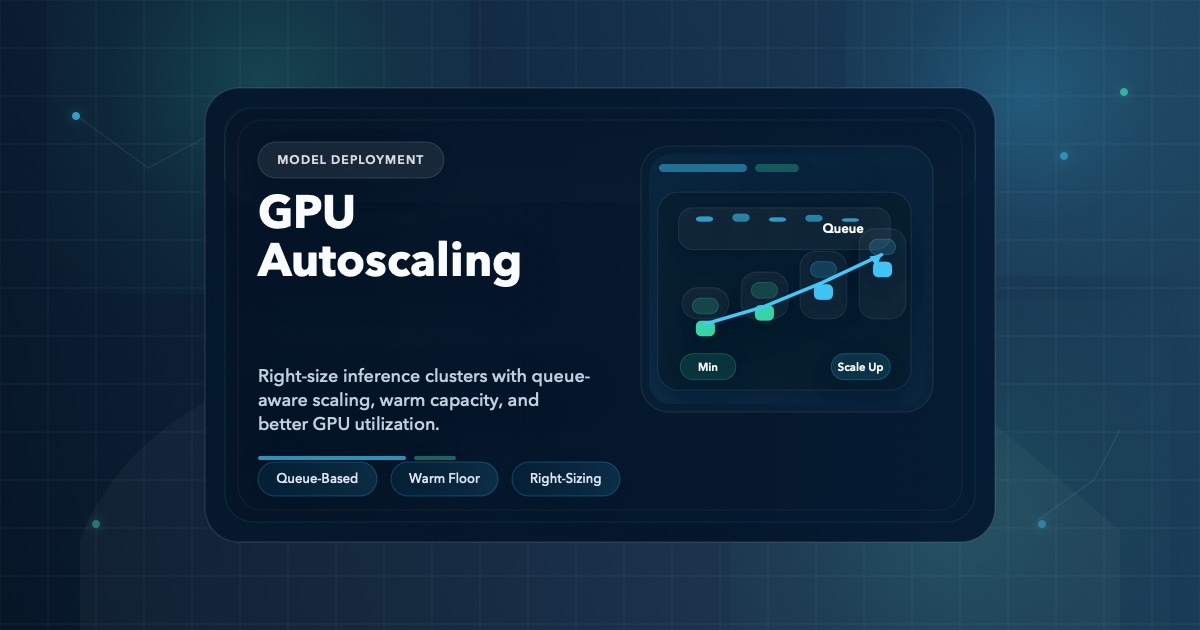
How to autoscale GPU-backed inference clusters without wasting money, including queue-based scaling, warm capacity, and right-sizing by workload profile.

Practical strategies for reducing GPU infrastructure costs — covering spot instances, GPU scheduling, model optimization, and right-sizing — without degrading inference quality.

How to serve many ML models on shared infrastructure without noisy-neighbor problems, unpredictable latency, or runaway GPU spend.

A practical guide to batching LLM inference workloads, including static batching, dynamic batching, queue controls, and when higher throughput starts hurting latency.
3/30/2026 • 6 min read
3/29/2026 • 8 min read
3/28/2026 • 6 min read
3/27/2026 • 5 min read
